Data’s value: how and why should we measure it?
Without knowing how to determine the value of data, how can we expect it be fairly distributed?
A 2017 report on the transport sector, produced by the ODI and Deloitte, illustrates why data sharing is so important. It states that an estimated £15bn is not being realised due to three main reasons: siloed thinking; a fear of breaching privacy, security and safety; and a belief that the costs of sharing data outweigh benefits. A belief that would be easier to challenge if we had a better understanding of how to value data.
The six most valuable companies in the world are now technology companies that rely upon data, while the companies dislodged at the top are now attempting to catch up and will need data to do that.
Data networks and the AI lock-in-loop are affecting market competition by creating new barriers to entry. These two effects are inherently linked; the data network effect is when a product becomes smarter the more it is used and the more data it receives from users. The AI lock-in-loop is the idea that this better product will then attract more users and therefore keep exploiting the network effects to improve. The loop will continue and make it increasingly difficult for new entrants to join the market.
There are many issues with the oft-made adage that ‘data is the new oil’. The two differ in many characteristics; data is superabundant compared to the finite oil supply and is non-rivalrous in nature.
Yet it is much more difficult to quantify the effect on GDP of investment in data than it is to quantify investment in more tangible assets, such as machinery – this is yet more value that is not fully captured. Similarly, Diane Coyle had previously concluded that current GDP estimates were failing to include the full extent of digital activities, or measure the further value when data is resold or reused. Moving forward new methods will have to be adopted to get a truer estimate of the value of data.
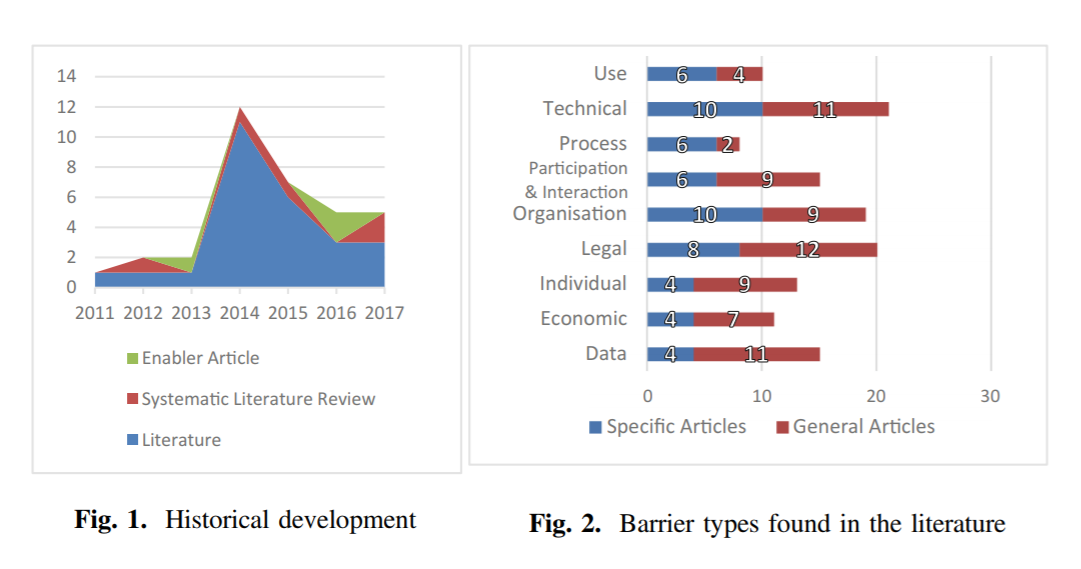
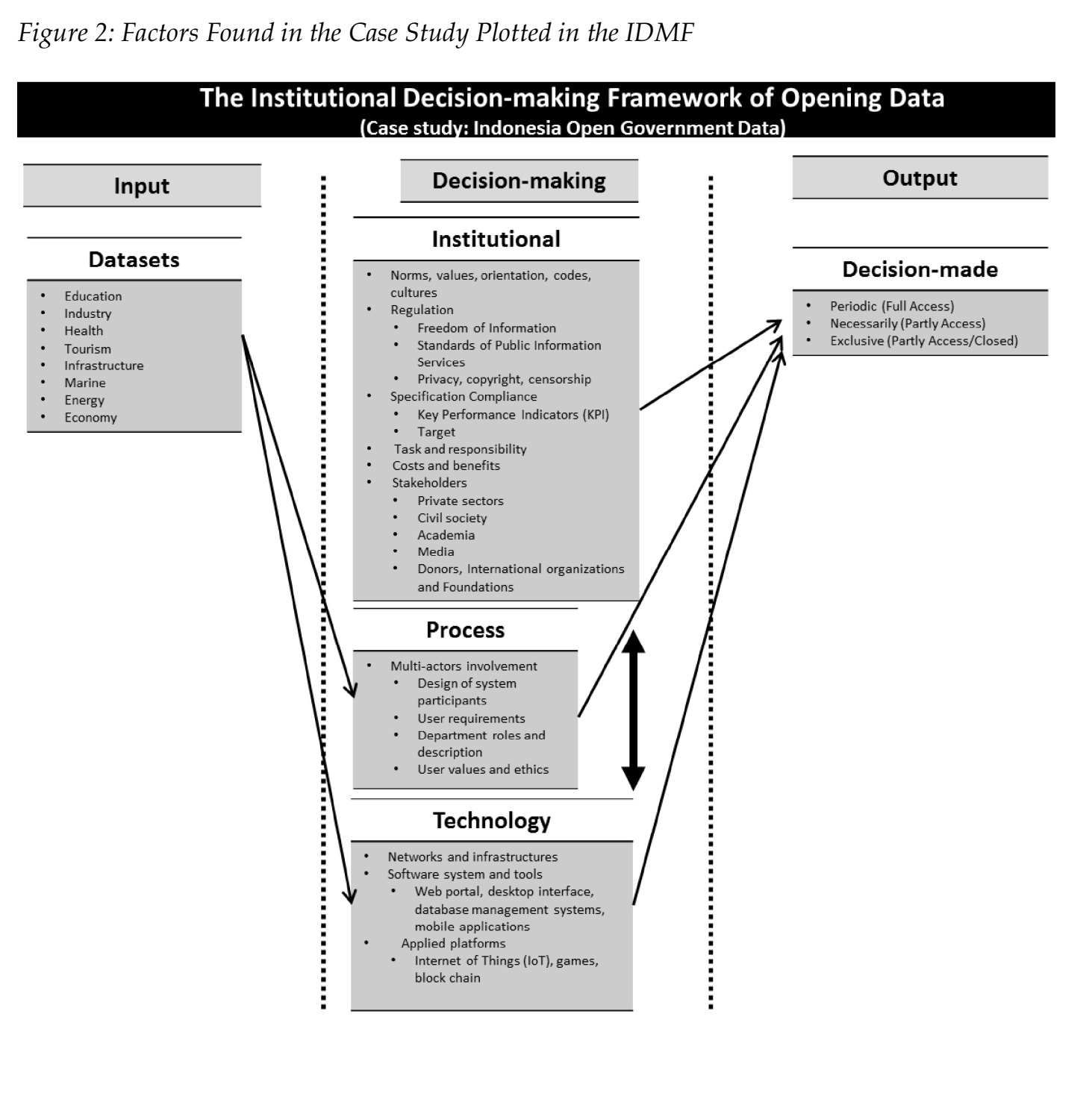


 [/center]
[/center]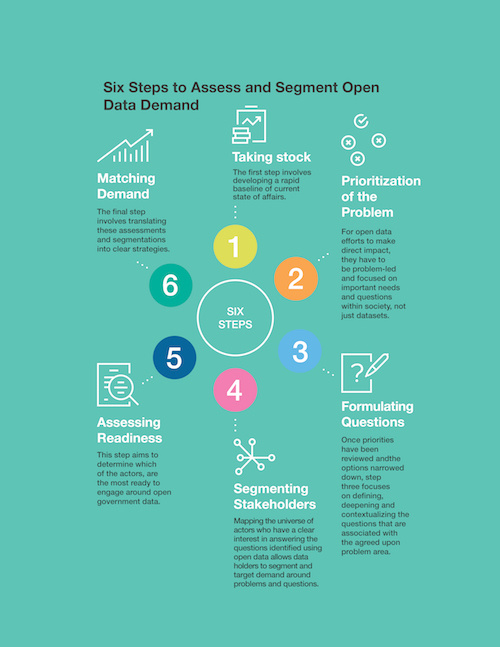
 [/center]
[/center]